Verwerking van subcategorisatie in HPSG
In HPSG is de subcategorisatie of valentie van een teken
een specificatie van de andere tekens (in aantal en soort) waarmee het teken
in kwestie gecombineerd moet worden om uiteindelijk gesatureerd
te worden.
Zo kunnen verschillende werkwoorden een combinatie aangaan met
verschillende complementen om een volledige, gesatureerde, zin te vormen.
De SUBCAT-lijst bij deze werkwoorden bevat de subcategorisatie-specificaties
voor de complementen waar in HPSG ook het subject onder valt.
Als aan alle subcategorisatie-eisen voldaan is bij het hoofd, spreken we van
volledige saturatie. Alle gesubcategoriseerde elementen zijn dan gesatureerd.
Uiteindelijk blijft er dus op zinsniveau een lege SUBCAT-lijst over:
SUBCAT< >.
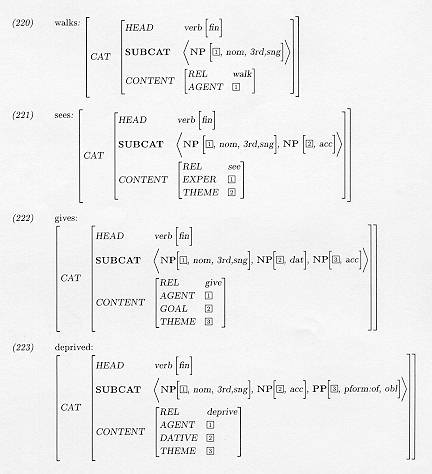
Hieronder zal ik enkele voorbeelden geven van lexicale ingangen van
werkwoorden met verschillende SUBCAT-lijsten:
In deze voorbeelden van lexicale ingangen zien we, dat de subcategorisatie bij ieder werkwoord weer anders kan zijn. Zo zien we verschillen tussen het aantal gesubcategoriseerde elementen, ook wel de valentie van het werkwoord het werkwoord genoemd (univalent, bivalent, trivalent). De aard van de elementen wordt eveneens gespecificeerd. Zo kan het zijn dat bij twee verschillende werkwoorden de specificatie van de elementen verschillend is, terwijl het aantal gesubcategoriseerde elementen hetzelfde is.
In HPSG is deze specificatie in hoofdzaak in termen van categorieën. Categorieselectie is nodig voor het beschrijven van de restrictieverschillen in syntactische categorie. Deze syntactische restricties vallen direct onder de subcategorisatie-eisen. Concreet komt dit erop neer dat in de SUBCAT-lijst de categorieën staan vermeld waarvoor het werkwoord subcategoriseert. Werkwoorden kunnen bijvoorbeeld NP's, PP's of VP's als complement nemen. Zo kan het derde argument van het werkwoord deprive alleen een PP zijn met als prepositieselectie PFORM=of. De SUBCAT-lijst bij de ingang van het werkwoord gives kan beknopt als volgt worden weergegeven: <NP1, NP2, NP3>. Er worden hier drie NP's geselecteerd. We kunnen vaststellen dat het subject evenals de objecten geselecteerd wordt door het werkwoord. Dit komt omdat het subject in HPSG ook gezien wordt als een complement.
Er kunnen naast nominale en prepositionele tekens (NP en PP) ook verbale tekens (VP en S) worden geselecteerd. Bijzinnen zijn in HPSG echter iets anders opgebouwd. Een bijzin worden gevormd door gebruik te maken van Markers. Een Marker is in HPSG de grammaticale relatie bij een teken dat aangeeft dat het teken er alleen om syntactische redenen staat. Een Marker heeft verder geen zelfstandige betekenis. Semantisch heeft een Marker dus geen inhoud. Er wordt iets gemarkeerd in de syntactische structuur. In dit geval leidt de Marker een ondergeschikte bijzin in. Het onderschikkende voegwoord van het type Marker subcategoriseert in HPSG voor de sententiële structuur, weergegeven met het symbool S. Voegwoordselectie wordt verder vastgelegd in de lexicale ingang van het werkwoord dat voor een bijzin subcategoriseert, en wel onder het attribuut MARKING.
Naamvaltoekenning en agreement wordt in HPSG eveneens via subcategorisatie beregeld. Bij iedere categorie is de passende (morfologische) naamval in de SUBCAT-lijst vastgelegd. In het voorbeeld van de ingang gives worden aan de drie NP's respectievelijk de naamvallen nominatief (NOM), datief (DAT) en accusatief (ACC) toegekend. De casustoekenning aan complementen (incl. de toekenning van de nominatiefnaamval aan het subject van een finiet werkwoord) wordt dus beschouwd als onderdeel van subcategorisatie. In HPSG is er geen aparte casustheorie. De eerste NP met de naamval NOM bevat hier verder de agreement-features persoon en getal. De agreement-relatie tussen het subject en het finiete werkwoord wordt dus samen met de subcategorisatie-eisen verwerkt.
De toekenning van semantische rollen wordt bewerkstelligd door structure sharing. Bij structure-sharing delen twee paden dezelfde structuur als hun gemeenschappelijke waarde. Er is dan sprake van teken-identiteit van waarden. In geval van roltoekenning deelt de parameter van een SUBCAT-element dezelfde waarde als die van het bijbehorende attribuut dat de rol aangeeft binnen het CONTENT-feature waarin de semantische predikaat-argumentrelatie zit vervat. Deze semantische rollen worden dus niet direct aan de complementen zelf toegekend maar juist aan de parameters ervan via structure-sharing.
Er moet verder opgemerkt worden dat de volgorde van het voorkomen van de elementen op de SUBCAT-lijst niet direct de complementvolgorde in de oppervlaktestructuur hoeft te weerspiegelen. In plaats daarvan correspondeert de volgorde op de SUBCAT-lijst met de traditionele notie van obliqueness van grammaticale relaties, van minst oblique tot meest oblique elementen. In geval van NP-complementen correspondeert het minst oblique element met de grammaticale functie `subject', het meer oblique element met `direct object' en het nog meer oblique element met `indirect object', enz. De elementen die voorkomen op de SUBCAT-lijst zijn dus geordend op de mate van obliqueness van de corresponderende grammaticale functies. Deze rangorde kan worden weergegeven in de Hierarchie van Obliqueness:
Het subject is in HPSG niet gedefinieerd als configurationele positie in de diepte-structuur maar eerder als de minst oblique complement van het relevante hoofd. Relatieve obliqueness wordt gemodelleerd door de rangorde of positie van het complement op de SUBCAT-lijst bij het hoofd.
Indirect wordt de relatie tussen obliqueness-volgorde en oppervlakte-constituentenvolgorde uitgedrukt in termen van taalspecifieke grammaticaregels en principes van Lineaire Precedentie (LP). De theorie van subcategorisatie in HPSG voorziet dus in een directe codering van hiërarchische relaties die nodig zijn voor het uitdrukken van deze volgorde-generalisatie.
De SUBCAT-waarde van een woordgroep is de SUBCAT-waarde van het lexicale hoofd (hier: het werkwoord) minus die specificaties waaraan al voldaan is door een bepaalde constituent in de woordgroep. Zo is de SUBCAT-waarde van de woordgroep verorber boterhammen alleen maar <NP[NOM]>. Ook al is de SUBCAT-waarde van het werkwoord verorber lexicaal gespecificeerd als <NP[NOM],NP[ACC]>, aan de specificatie NP[ACC] wordt al voldaan binnen de woordgroep door het object boterhammen. Op dezelfde manier is de SUBCAT-waarde van Jan verorbert boterhammen een lege lijst < >, waarbij nu aan de resterende specificatie NP[NOM] is voldaan door het subject Jan. Aan alle specificaties van subcategorisatie is uiteindelijk voldaan in de structuur. De zin is dan ook volledig gesatureerd.
In HPSG wordt de overdracht van deze subcategorisatie-informatie bovenop de projectiepaden beregeld door het volgende principe:

Hier betekent APPEND(L1,L2) voor de twee lijsten L1 en L2 de concatenatie of samenvoeging van deze twee lijsten in de aangegeven volgorde. Het Subcategorisatieprincipe in \hetvb eist dat van iedere structuur met een hoofd (headed structure) de woordgroep de SUBCAT-waarde krijgt die gelijk is aan de SUBCAT-waarde van het hoofd minus de specificaties waaraan voldaan wordt door de complement-dochters. In een woordgroep met een hoofd is de SUBCAT-waarde van de HEAD-dochter dus een concatenatie van de SUBCAT-lijsten van de moederknoop en van de COMPLEMENT-dochters.
Bovendien dwingt de structure sharing, aangegeven met de tags, af dat de informatie van elke complement-dochter daadwerkelijk wordt geünificeerd met de corresponderende subcategorisatiespecificatie op het hoofd. Een teken kan dus alleen voldoen aan een subcategorisatiespecificatie op een bepaald hoofd als het consistent is met de specificatie; anders resulteert dit in een falen van unificatie, hetgeen een schending is van het Subcategorisatie-principe. De subcategorisatie-eisen van het lexicale hoofd worden dus volgens het Subcat-Principe nagegaan en gecontroleerd.
Uiteindelijk moeten alle elementen van de SUBCAT-lijst gesatureerd zijn: SUBCAT < >. Dit kan alleen als alle elementen die aan de subcategorisatiespecificaties voldoen, gevonden worden in de structuur. De SUBCAT-lijst moet met andere woorden na het satureren van alle complementen leeg zijn.
Het controleren van deze subcategorisatie-eisen kan in stappen vastgelegd worden met Schema's van Immediate Dominance, ook wel ID-regels genoemd. Deze grammatica-regels dienen als schema's van toelaatbare locale bomen of configuraties van immediate constituency. Hieronder laat ik de twee belangrijkste Schema's zien die onder andere de informatie weergeven van de saturatie van complementen.
Zo drukt Schema 1 een volledig gesatureerde woordgroep uit. De DTRS-waarde is van het type head-comp en de HEAD-dochter is een phrasal sign. De SUBCAT-lijst van de COMPLEMENT-dochters is een lijst is met lengte 1: alleen het subject hoeft nog maar gesatureerd te worden. Als het subject is gevonden, blijft uiteindelijk een lege SUBCAT-lijst over op de moederknoop van deze locale boom. Dit schema is te vergelijken met
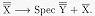
Schema 1 levert de volgende (locale) boomstructuur op:
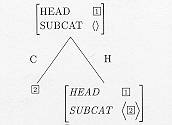
In Schema 1 wordt het subject, dat voldoet aan de laatst overblijvende specificatie op de SUBCAT-lijst, gesatureerd. Als alles dus gevonden is in de structuur, wordt aan alle subcategorisatie-eisen voldaan.
Het volgende algemene ID-regel legt de saturatie van de andere complementen vast. Schema 2 geeft een bijna gesatureerde woordgroep weer. De DTRS-waarde is van het type head-comp-struc en de HEAD-dochter is een lexicaal teken is (hier: het werkwoord). Alleen het subject blijft nog over. Daarom heeft de SUBCAT-lijst van moederknoop van deze locale boom de lengte 1: het bevat namelijk nog één specificatie die nodig is voor het subject. Dit schema is de vergelijken met:
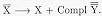
Schema 2 levert de volgende (locale) boomstructuur op:
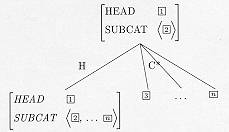
Het subject moet dus nog gevonden worden. Zoals we gezien hebben, wordt in Schema 1 het subject daadwerkelijk gevonden. Als deze Schema's beide toegepast kunnen worden, is er dus sprake van volledige saturatie.
Hierboven was alleen uitgegaan van zelfstandige werkwoorden. Het is duidelijk dat deze werkwoorden subcategoriseren voor argumenten in termen van categorieën. De vraag is of hulpwerkwoorden in HPSG ook subcategoriseren voor argumenten. We zouden dan een specificatie in de SUBCAT-lijst verwachten. Het is wel zo, dat een hulpwerkwoord een VP-complement selecteert. Aanvankelijk werd dan ook dit VP-complement opgenomen in de SUBCAT-lijst bij de ingang van het hulpwerkwoord [Pollard & Sag 1987, p.124-126]. De hulpwerkwoorden werden hier dus steeds als hoofd beschouwd die een VP als complement namen. Variatie in deze selectie van VP-complementen is verder zichtbaar in de vorm van de werkwoorden bij de hulpwerkwoorden. Een hulpwerkwoord roept telkens een verbale verwachting op voor de werkwoordsvorm (VFORM) van het hoofd van de geselecteerde VP. Perfectieve hulpwerkwoorden selecteren VP-complementen waarvan het hoofd een voltooid deelwoord is: SUBCAT < NP, VP[VFORM(PSP)] >. Modale hulpwerkwoorden selecteren VP-complementen waarvan het hoofd infiniet is: SUBCAT < NP, VP[VFORM(INF)] >.
De vraag of we bij hulpwerkwoorden wel echt kunnen spreken van subcategorisatie, speelt ook in het HPSG-kader. Er is immers bij hulpwerkwoorden geen sprake van subcategorisatie in termen van argumenten. Bovendien delen hulpwerkwoorden geen semantische rollen uit. De verbale verwachting van hulpwerkwoorden zou misschien niet in de SUBCAT-lijst opgenomen moeten worden. Deze SUBCAT-lijst reserveren we dan voor de selectie van argumenten die verbonden zijn met semantische rollen. Hulpwerkwoorden kunnen alleen tijd, aspect, modaliteit, passiviteit en causaliteit toevoegen aan het geheel. Het is dan niet mogelijk om hulpwerkwoorden als hoofd te beschouwen van een VP. Een alternatief is om hulpwerkwoorden als Markers te behandelen die de SUBCAT-lijst van zelfstandige werkwoorden onaangetast laten. Over deze kwestie van hulpwerkwoorden is in het HPSG-kader, evenals in andere taaltheoretische kaders, nog niet het laatste woord gesproken. Deze en meer kwesties zullen nader onderzoek behoeven.
Optionaliteit is een andere kwestie. In HPSG wordt er een onderscheid gemaakt tussen twee verschillende soorten van niet-uitgedrukte complementen [Pollard & Sag 1987]. De eerste soort gaat om ontologische noodzakelijkheid van complementen. Er zijn complementen die geassocieerd worden met semantische rollen die ontologisch noodzakelijk zijn, zo dat zelfs als het complement in kwestie niet in de oppervlaktestructuur wordt uitgedrukt, de beschreven situatie er een moet zijn waar een of ander object de rol in kwestie speelt. Een voorbeeld hiervan is het object bij eten (to eat). In de eet-handeling zal men altijd iets eten. Dit object zal dus altijd moeten blijken uit de context van de situatie. Er zijn echter ook ontologisch niet-noodzakelijke argumenten. Een voorbeeld hiervan is het object bij trappen (to kick). Men kan namelijk trappen zonder dat men iets in het bijzonder trapt. Elke relatie heeft een karakteristiek aantal argumenten. Als ze echter ontologisch niet-noodzakelijk zijn, is het beter om te zeggen dat elke relatie een karakteristiek maximum aantal argumenten heeft. Een ander aantal argumenten van een relatie komt naar voren indien een of meer niet-noodzakelijke rollen oningevuld blijft. Sommige relaties hebben dus met andere woorden een variabel aantal argumenten.
Hiertegenover staat de tweede soort van niet-uitgedrukte complementen: de optionele complementen. We hebben dan met werkwoorden te maken die object-deletie toestaan. Optionaliteit wordt in HPSG weergegeven bij specificaties in de SUBCAT-lijst van lexicale ingangen. Ieder complement dat optioneel is, wordt namelijk gemarkeerd met een optionaliteitsteken. Zo kan de SUBCAT-lijst bij het werkwoord eten, dat een optioneel object heeft, er als volgt uitzien: SUBCAT<NP,(NP)>.
Het probleem bij optionaliteit is dat complementen in HPSG altijd via een parameter gelinkt zijn met de semantische rollen. Als een object echter niet aanwezig is in de oppervlaktestructuur, kan de rol bij dit object nog wel aanwezig zijn in de predikaat-argumentrelatie. De rol kan namelijk volgen uit de context van de situatie en blijkt dus mee te spelen in de handeling. Het kan echter ook zijn dat bij afwezigheid van het object, dit object geen rol speelt in de situatie. In dat geval zou optionaliteit ook doorgevoerd moeten worden op semantisch niveau. Dit is lastig in HPSG omdat subcategorisatie (syntactische selectie) en roltoekenning (semantische selectie) via unificatie en structure-sharing met elkaar "verstrengeld" zijn. Er moeten kunstgrepen worden toegepast om dit probleem op te lossen [Pollard & Sag 1987, p.133]. Bovendien ligt optionaliteit, zoals uit het bovenstaande onderscheid tussen verschillende soorten niet-uitgedrukte complementen bleek, niet op het semantische maar op het lexicale of syntactische vlak.
Een andere benadering is om deze werkwoorden met of zonder objecten als aparte varianten van elkaar te beschouwen en ze dus in aparte lexicale ingangen op te nemen, waar het verschil tussen beide ingangen zit in het wel of niet voorkomen van het object in de SUBCAT-lijst. We krijgen dan de volgende twee varianten: SUBCAT < NP > en SUBCAT < NP NP >. Het grote nadeel hiervan is dat we een generalisatie missen en er redundantie in het lexicon optreedt. Voor alle werkwoorden met optionale complementen moet een dergelijke opsplitsing in varianten in het lexicon worden opgenomen. Soms is zo'n opsplitsing in HPSG onvermijdelijk, zoals in de polyvalentie-gevallen waarbij twee of meer in vorm hetzelfde zijnde werkwoorden verschillende betekenissen hebben en andere semantische rollen toekennen aan hun argumenten. Als laatste redmiddel zouden we dan gebruik kunnen maken van lexicale regels. Dit kan alleen als er sprake is van een grote klasse van werkwoorden waar de lexicale regel van toepassing op kan zijn. Bij idiosyncratische gevallen is deze benadering echter weer uitgesloten.
We zouden voor ieder werkwoord dat een andere SUBCAT-lijst heeft een nieuwe aparte ingang kunnen aannemen. In HPSG wordt echter ook geprobeerd om generalisaties te vinden voor grote klassen werkwoorden. Varianten kunnen worden afgeleid van een SUBCAT-lijst door middel van lexicale regels. Lexicale regels zijn regels die nieuwe featurestructuren afleiden in het lexicon. Zo is de versie van passivisatie in HPSG is globaal dezelfde als die van andere niet-transformationele theorieën, waar een lexicale regel wordt voorgesteld die van de actieve vorm de passieve vorm afleidt.

De semantische inhoud wordt eenvoudigweg overgenomen van de inputvorm zonder verandering. De fonologie van de passieve vorm wordt bepaald van de inputvorm door dezelfde morfologische operatie als het verleden deelwoord (past participle). De kern van de lexicale regel voor passivisatie zit in de subcategorisatie: het subject van de inputvorm wordt gewoon van de SUBCAT-lijst afgehaald en zijn index wordt toegekend aan een nieuwe categorie, namelijk de optionele PP[by].
In het algemeen kunnen op deze manier in HPSG lexicale regels gebruikt worden, zoals in LFG, om polyvalentie-patronen te verantwoorden die van toepassing zijn op een gehele woordklasse. Zo kan de alternatie tussen causatieve transitieve werkwoorden en corresponderende niet-causatieve intransitieve werkwoorden (iemand breekt het raam tegenover het raam breekt) verantwoord worden door een lexicale regel als Detransitivisatie of Ergativisatie waarvan het effect op subcategorisatie in hoofdzaak hetzelfde is als de passivisatieregel (met als uitzondering dat er geen optionele PP wordt geïntroduceerd). Er moet wel opgemerkt worden dat de varianten hier lexicaal worden afgeleid en niet structureel. In wezen zorgt een lexicale regel ervoor dat van een lexicale ingang een nieuwe lexicale ingang wordt afgeleid. Uiteindelijk hebben we na toepassing van lexicale regels dus weer de opsplitsingen in de ingangen die we voorheen hadden. De redundantie in de ingangen is nu echter (tijdelijk) weggenomen via deze afleidregels.
Met het bovenstaande hoop ik duidelijk te hebben gemaakt
hoe subcategorisatie in HPSG wordt verwerkt.
Vervolg: Inleiding G&B

| 
|