Doctoraalscriptie (1996)
K.U. Nijmegen
Subcategorisatie
Een onderzoek naar SUBCATEGORISATIE en de verwerking ervan in een NLP-systeem.
Simon van Dreumel
Verwerking van subcategorisatie in LFG
Subcategorisatie is binnen het LFG-kader de uitwerking van de voorwaarden
waaronder een lexicaal element in een bepaalde omgeving kan worden
geïnserteerd. In LFG wordt subcategorisatie vastgelegd in termen van
grammatische functies.
In LFG zijn er twee restricties op f-structuren die ervoor zorgen dat er
voldaan wordt aan de subcategorisatie-eisen van het werkwoord.
Dit zijn de eisen van Volledigheid en Coherentie.
Met behulp van de notie `grammaticale functie' wordt de schending van
de subcategorisatie-eisen van het werkwoord in de volgende zinnen voorspeld.
| | * | Peter verorbert
|
| | * | Peter lacht Sofie
|
Het werkwoord verorberen drukt een relatie uit tussen twee
argumenten, die verbonden zijn met de grammatische functies
subject en object. In het voorbeeld ontbreekt het object, terwijl dit
object verplicht aanwezig moet zijn bij het werkwoord verorberen.
Om die reden is de zin ongrammaticaal.
Het werkwoord lachen drukt echter een relatie uit met één argument
dat verbonden is met de grammatische functie subject. In het voorbeeld is
er nog een constituent aanwezig `Sofie', op de plaats waar gewoonlijk het
object staat. Het werkwoord kan alleen een subject nemen, in dit geval
de NP `Peter'. Doordat de NP `Sofie' geen relatie kan hebben met het
werkwoord, is de zin ongrammaticaal.
In LFG zijn alle grammaticale relaties in een f-structuur vertegenwoordigd
door de attributen zoals SUBJ (subject) en OBJ (object).
Het attribuut PRED heeft als waarde een semantische vorm.
De PRED-waarde is te beschouwen als semantische kern van een woordgroep.
Zo is bijvoorbeeld `PETER' de typische PRED-waarde voor een
zelfstandig naamwoord.
De PRED-waarde 'VERORBEREN <(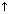 SUBJ)(OBJ)>'
hoort bij een werkwoord. In de laatste semantische vorm zien we achter
VERORBEREN de predikaat-argumentstructuur: VERORBEREN heeft twee
argumentposities, die
door (SUBJ) en (OBJ) worden
ingenomen. Na de substitutie van de pijltjes door de namen van de
f-structuren, duiden de schema's aan welke elementen de argumentpositie gaan
innemen.
SUBJ)(OBJ)>'
hoort bij een werkwoord. In de laatste semantische vorm zien we achter
VERORBEREN de predikaat-argumentstructuur: VERORBEREN heeft twee
argumentposities, die
door (SUBJ) en (OBJ) worden
ingenomen. Na de substitutie van de pijltjes door de namen van de
f-structuren, duiden de schema's aan welke elementen de argumentpositie gaan
innemen.
We zouden voor de zin 'Peter verorbert' de volgende f-structuur kunnen
krijgen:

De argumentposities worden geacht bezet te worden door de functionele
elementen (f1 SUBJ) en (f1 OBJ).
We zien dat f1 geen waarde toekent aan het attribuut OBJ. De naam
(f1 OBJ) heeft dus geen verwijzing. Met andere woorden, de
tweede argumentpositie wordt niet bezet in de predikaat-argumentstructuur.
Als een argumentpositie in een predikaat-argumentstructuur niet wordt
bezet, dan is de f-structuur onvolledig. Iedere f-structuur die een
onvolledige f-structuur bevat, is ook weer onvolledig. Een welgevormde
f-structuur moet echter volledig zijn.
Hier wordt de eis van Volledigheid geschonden.
Deze eis zorgt er dus voor dat er voldoende argumenten
zijn om aan de eisen van predikaat-argumentstructuur, gegeven als waarde
bij het werkwoord, te voldoen.
De eis van Coherentie zorgt ervoor dat er niet te veel argumenten zijn voor
de beschikbare argumentpositie.
In het tweede voorbeeld zijn teveel argumenten voor de beschikbare
argumentposities.
De f-structuur ervan is als volgt.

Er is maar één argumentpositie beschikbaar in de
predikaat-argumentstructuur 'LACHEN <(f1 SUBJ)>'.
Deze is bezet door (f1 SUBJ).
Voor de f-structuur is er echter nog een functie gespecificeerd, namelijk
het object (het attribuut OBJ met als waarde f3).
Aangezien de enige plaats bij het werkwoord al bezet is, kan deze functie
niet geregeerd worden. Het attribuut OBJ komt immers niet voor in de
predikaat-argumentstructuur van lachen.
De f-structuur is dan incoherent en volgens de eis van Coherentie
onaanvaardbaar. Iedere f-structuur
die een incoherente f-structuur bevat, is zelf weer incoherent.
| | Grammaticaliteitsconditie:
Een string is grammaticaal alleen
als er een volledige en coherente f-structuur aan toegekend is.
|
Als er aan de grammaticaliteitsconditie wordt voldaan, dan voldoet de
structuur aan de subctategorisatie-eisen.
In het LFG-kader wordt aangenomen dat subcategorisatie alleen gaat
om het selecteren van grammaticale functies zoals
subject (SUBJ), object (OBJ),
indirect object (OBJ2),
prepositioneel object (POBJ).
Er zijn echter redenen waarom subcategorisatierestricties niet kunnen worden
uitgedrukt in puur functionele termen [Pollard & Sag 1987].
Het is duidelijk dat er subcategorisatierestricties zijn die
de verschillen in syntactische categorie teweegbrengen maar die niet
teruggevoerd kunnen worden tot functionele onderscheidingen.
Allereerst vormt categorieselectie een subcategorisatierestrictie op
de argumenten van het werkwoord. Dit dient dus eveneens opgenomen te worden
in een theorie van subcategorisatie.
In de LFG-benadering wordt deze categorieselectie echter verwaarloosd.
LFG verantwoordt alleen de selectie van functies door het werkwoord.
Nu zouden categoriale verschillen gekoppeld kunnen worden aan
de verschillende functies. Het probleem hierbij is dat de verschillende
categorieën niet eenduidig op de bestaande set van grammaticale
functies afgebeeld kunnen worden.
Er is namelijk geen één-op-één-relatie tussen functie en categorie.
Nu zouden de categoriale verschillen meegecodeerd kunnen worden
in de functienamen, maar dan zijn we eigenlijk categoriale verschillen
aan het beschrijven in termen van "functies".
Een voorbeeld hiervan is het onderscheid tussen direct object en
prepositioneel object. Dit is in wezen een categoriaal verschil en niet
zozeer een functioneel verschil.
Het zijn beide namelijk objecten, waarbij in het geval van een
direct object een NP wordt geselecteerd en in het geval van een
prepositioneel object een PP.
Er is hier dus een verschil in categorie, namelijk NP tegenover PP.
Als nieuwe functienamen worden ingevoerd om de categoriale verschillen
in een zuiver functionele benadering te kunnen verantwoorden,
worden de subtypen functie en categorie niet van elkaar gescheiden gehouden.
Eigenlijk wordt dan voor ieder principieel categoriaal verschil een
functioneel verschil gecreëerd. De categorie wordt dan gecodeerd in
de functienamen. De nieuwe functienamen zijn overbodig, omdat ze coderen
wat al wordt uitgedrukt via categorieselectie. Categorieselectie zou hier
dus al volstaan. We moeten geen extra elementen toevoegen die niet nodig zijn
voor een goede verklaring van de feiten (Ockhams Scheermes).
Bovendien zouden de fijnmazigere subcategorisatie-restricties, zoals
prepositieselectie, niet meegenomen kunnen worden als alleen gekozen wordt
voor de gangbare grammaticale functies.
Voor ieder object met een door het werkwoord geselecteerd voorzetsel
zou dan een nieuwe aparte functienaam bedacht moeten worden. Dit leidt weer
tot een absurd aantal overbodige functienamen en mist iedere generalisatie.
Categorieselectie en prepositieselectie dienen dus afzonderlijk opgenomen
te worden in de theorie.
Een benadering waarin subcategorisatie alleen wordt uitgedrukt in termen
van grammaticale functies, zal dus tekortschieten in de beschrijving van
subcategorisatie omdat dan juist de meer verfijnde
subcategorisatieverschillen niet tot uitdrukking gebracht kunnen worden.
Functies zouden gebruikt kunnen worden als abstractie over categorieën
op bepaalde vaste argumentposities. Maar het is de vraag of we hiervoor
grammaticale functies moeten gebruiken.
Het gebruik van de bestaande set grammaticale functies kent namelijk
zo zijn nadelen.
Allereerst zijn niet alle functionele onderscheidingen even relevant,
zoals we al zagen bij het onderscheid direct object en prepositioneel object
waar geen sprake is van een functioneel verschil.
Verder worden in het gemaakte onderscheid in functies naast syntactische
criteria ook nog eens semantische aspecten meegenomen.
Bovendien zijn functies af te leiden uit de syntactische structuur.
Functies geven namelijk relaties weer tussen categorieën.
Deze relaties zijn af te leiden uit boomstructuurconfiguraties.
Er zou redundantie ontstaan als deze relaties nog een keer uitgedrukt worden
in een functielabel. De relaties in de boomstructuur volstaan dus.
Aparte functielabels zijn dus niet nodig,
omdat de hiërarchische syntactische structuur al voldoende informatie
geeft over de relaties tussen categorieën (knopen of posities).
Zoals we in het eerste hoofdstuk al hebben vastgesteld lenen argumenten
(of: argumentposities) zich beter voor het abstraheren over categorieën.
Deze typering in argumenten is een directe weergave van wat het
werkwoord in eerste instantie selecteert: een bepaald werkwoord neemt
een maximaal aantal argumenten van een bepaalde aard.
Bovendien maakt deze typering goede generalisaties mogelijk.
Optionaliteit hoeft nu alleen maar van toepassing te zijn op argumenten en
niet op alle mogelijke categoriale realisaties van die argumenten.
Semantische rollen kunnen direct worden toegekend aan de argumenten.
En uiteindelijk kunnen algemene regels abstracter geformuleerd worden,
bijvoorbeeld alleen in termen van argumenten.
De hiërarchie en volgorde van de categorieën (c-structuur) wordt in LFG
vastgelegd in herschrijfregels. In deze herschrijfregels heeft iedere
categorie aan de rechterkant van de herschrijfpijl een metaschema.
Deze metaschema's zorgen voor de koppeling van de c-structuur aan de
f-structuur. Door deze verstrengeling volgt de volgorde van de grammaticale
functies indirect uit die van de categorieën.
De volgorde van de grammaticale functies is in LFG af te leiden uit de
Functionele Hiërarchie: subject – indirect object –
direct object – prepositioneel object.
Een soortgelijke hiërarchie zullen we terug zien komen in de
behandeling van HPSG (hierarchy of obliqueness).
In LFG worden adjuncten onderscheiden van complementen.
De complementen worden opgenomen bij de semantische kernen zoals het
werkwoord. In LFG heeft iedere semantische kern het PRED-attribuut.
Dit PRED-attribuut heeft als waarde een semantische inhoud waarin de
subcategorisatie van complementen in termen van functies wordt vastgelegd.
De argumenten in de structuur worden verbonden met deze functies.
Adjuncten staan hier los van. Als metaschema hebben ze dan ook
= 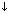 .
Dit is een vorm van cancelling. De betekenis van een uiting wordt
niet gewijzigd na het toevoegen van een adjunct.
De semantische bijdrage blijft dus constant.
Adjuncten kunnen vrijelijk toegevoegd worden en zijn semantisch autonoom.
Dit is niet het geval bij complementen. Complementen worden immers
geselecteerd door het werkwoord. Het hangt van het werkwoord af of en welke
complementen bij dit werkwoord kunnen voorkomen in de structuur.
Terwijl adjuncten semantisch autonoom zijn, zijn complementen
afhankelijkheden bij het werkwoord (predikaat-argumentrelatie).
In LFG in de scheiding tussen complementen en adjuncten strikt.
Of het is een complement of het is een adjunct.
Tussenvormen zoals adjunct-argumenten of adjunct-complementen, die
zowel de eigenschappen van complementen als van adjuncten vertonen,
kunnen voor LFG problemen opleveren. Doordat hier een strikte tweedeling
wordt aangenomen, zal de tussengroep ondergebracht worden
onder één van de twee klassen. De eigenschappen die de
tussengroep juist deelt met de andere klasse worden dan buiten beschouwing
gelaten. Hoogstwaarschijnlijk zullen in LFG de adjunct-complementen
ondergebracht worden onder de groep complementen.
Een alternatief is om beide mogelijkheden apart op te nemen in het lexicon.
Er is dan een opsplitsing in twee verschillende lexicale ingangen.
Bij optionele complementen zal binnen LFG voor een soortgelijke aanpak
gekozen worden: één lexicale ingang waar het complement bij
het subcategorisatieschema staat en één lexicale ingang waar
het complement ontbreekt. Hier gaat het echter om hetzelfde werkwoord.
We missen dan ook een enorme generalisatie door al deze verschillende
mogelijkheden bij een en hetzelfde werkwoord in aparte lexicale ingangen
uit te schrijven. Het zou beter zijn om varianten hoe dan ook af te leiden.
.
Dit is een vorm van cancelling. De betekenis van een uiting wordt
niet gewijzigd na het toevoegen van een adjunct.
De semantische bijdrage blijft dus constant.
Adjuncten kunnen vrijelijk toegevoegd worden en zijn semantisch autonoom.
Dit is niet het geval bij complementen. Complementen worden immers
geselecteerd door het werkwoord. Het hangt van het werkwoord af of en welke
complementen bij dit werkwoord kunnen voorkomen in de structuur.
Terwijl adjuncten semantisch autonoom zijn, zijn complementen
afhankelijkheden bij het werkwoord (predikaat-argumentrelatie).
In LFG in de scheiding tussen complementen en adjuncten strikt.
Of het is een complement of het is een adjunct.
Tussenvormen zoals adjunct-argumenten of adjunct-complementen, die
zowel de eigenschappen van complementen als van adjuncten vertonen,
kunnen voor LFG problemen opleveren. Doordat hier een strikte tweedeling
wordt aangenomen, zal de tussengroep ondergebracht worden
onder één van de twee klassen. De eigenschappen die de
tussengroep juist deelt met de andere klasse worden dan buiten beschouwing
gelaten. Hoogstwaarschijnlijk zullen in LFG de adjunct-complementen
ondergebracht worden onder de groep complementen.
Een alternatief is om beide mogelijkheden apart op te nemen in het lexicon.
Er is dan een opsplitsing in twee verschillende lexicale ingangen.
Bij optionele complementen zal binnen LFG voor een soortgelijke aanpak
gekozen worden: één lexicale ingang waar het complement bij
het subcategorisatieschema staat en één lexicale ingang waar
het complement ontbreekt. Hier gaat het echter om hetzelfde werkwoord.
We missen dan ook een enorme generalisatie door al deze verschillende
mogelijkheden bij een en hetzelfde werkwoord in aparte lexicale ingangen
uit te schrijven. Het zou beter zijn om varianten hoe dan ook af te leiden.
Binnen LFG wordt uitgegaan van een lexicalistische benadering:
alle locale afhankelijkheden dienen in het lexicon opgenomen te worden.
Passief (naast actief), ergatief (naast causatief) en dative-shift
zijn volgens LFG varianten die locaal afgeleid kunnen worden. Dit gebeurt
dan ook met behulp van lexicale regels. Dit zijn redundantie-regels die
toegepast op lexicale ingangen weer nieuwe lexicale ingangen opleveren.
We kunnen hier dus spreken van lexicale afleidbaarheid.
Er wordt in de lexicale regels gebruik gemaakt van primitieven als
'subject' (SUBJ), 'object' (OBJ)
en 'indirect object' (OBJ2).
De benadering staat haaks op de meer structurele benadering zoals in GB
waarin juist geen primitieven gebruikt worden maar eerder
algemene principes gelden die omzettingen in de structuur
(MOVE  ,
zoals NP-verplaatsing bij passivisatie en ergativisatie, noodzakelijk
maken. De verplaatsingen volgen dan uit de principes en worden niet
afzonderlijk gestipuleerd met redundantieregels in termen van
primitieven [T. Hoekstra 1984].
,
zoals NP-verplaatsing bij passivisatie en ergativisatie, noodzakelijk
maken. De verplaatsingen volgen dan uit de principes en worden niet
afzonderlijk gestipuleerd met redundantieregels in termen van
primitieven [T. Hoekstra 1984].
Een kader dat de niet-derivatieve (niet-transformationele) deelt met LFG
is het HPSG-kader. HPSG heeft bepaalde kenmerken overgenomen van LFG.
In de volgende paragraaf zullen we het HPSG-kader nader bekijken.
Vervolg: Inleiding in HPSG
Voor opmerkingen of vragen over deze pagina kunt u contact opnemen
met Simon van Dreumel
Laatst gewijzigd op 25 augustus 2025

