Doctoraalscriptie (1996)
K.U. Nijmegen
Subcategorisatie
Een onderzoek naar SUBCATEGORISATIE en de verwerking ervan in een NLP-systeem.
Simon van Dreumel
Verwerking van subcategorisatie in AMAZON/CASUS
In CASUS worden volgens het cyclische principe alle
sententiële knopen (SE-knopen) van boven naar beneden voor
interpretatie afgewerkt. Telkens wordt dus een SE-domein op
één niveau afgebakend van de subbomen van de verder ingebedde
SE-knopen. Alle SE-cycli worden in principe op dezelfde manier
afgehandeld. In de grammatica Interpret-Cycle worden in
iedere cyclus de volgende stappen genomen
[Coppen 1991]:
- Er wordt geïtereerd over het casusframe (SF) van het
hoofdwerkwoord uit de cyclus; alle lexicale informatie (hier:
welke rollen het werkwoord uitdeelt en welke categorieën als
mogelijke kandidaten gelden) moet op ieder niveau worden
geprojecteerd op de structuur [ProjectiePrincipe]
- Analyseer de cyclus met en zonder het gealloceerde WH-element
[WH-spoor]
- Itereer over de verschillende volgorden van de constituenten na
terugplaatsing ervan [MOVE
 ]
]
- Voeg PRO in als eerste kandidaat onder MI, in geval van een
controlestructuur [PRO-insertie in infinitiefzin]
- Alle casusrollen worden toegekend aan de constituenten
onder controle van selectierestricties en congruentie
[Assign Case] (zie hieronder meer hierover)
- De "laatste redding" wordt toegepast in geval van raising- en
controlestructuren:
geraisde constituenten en constituenten die op de grens van een
transparant infinitiefcomplement staan, worden gelowerd
- Uiteindelijk wordt gecontroleerd of alle casusrollen zijn
toegekend [
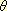 -criterium] en alle constituenten een rol hebben bij
het werkwoord [Casusfilter].
-criterium] en alle constituenten een rol hebben bij
het werkwoord [Casusfilter].
We zullen de toepassing van Assign-Case nader bekijken. In
CASUS(90) is de volgende structuur het uitgangspunt voor
casustoekenning:

In AMAZON/CASUS is de vaste structuur van argumenten met hun
rollen in een apart lexicon opgeslagen: het SF-lexicon
(SF= Semantic Functie/Frame). Aan het begin van iedere cyclus
wordt dan ook uit het lexicon de Semantische Functie (SF) of
casusframe van het betreffende hoofdwerkwoord opgehaald. De
volgorde die in een SF-frame aangehouden wordt, is in principe de
volgorde van de elementen onder MI. Welke rollen er worden
uitgedeeld, en in welke volgorde dit gebeurt, is dus afhankelijk
van het opgehaalde S-frame van het betreffende hoofdwerkwoord in
de cyclus. De informatie van het SF-frame van het hoofdwerkwoord
van de cyclus wordt in de boomstructuur onder de SF-knoop
geplaatst, zoals aangegeven in \hetvb. De SF-knoop staat vóór
de knopen TOP, MI en UL.
Het doel van Assign-Case is dat de eerste lege casuspositie
gevuld wordt met iedere bereikbare en geschikte casuskandidaat. De
positie met een semantische casusrol, of kortweg casuspositie,
onder SF is al gelabeld. De lege knoop bevat
namelijk informatie over welke categorieën met de bijbehorende
restricties in de vorm van syntactische en semantische features,
in aanmerking komen voor die betreffende casusrol. Onder een
rechterzuster van SF wordt een kandidaat gezocht waaraan de
casusrol kan worden toegekend. Er wordt dus onder TOP, MI en UL
gezocht naar een geschikte kandidaat. Als deze rechterzuster van
SF een MI is, waaronder meer kandidaten kunnen staan, mag de
kandidaat zelf geen linkerzusters hebben, met andere woorden: de
kandidaat moet dan helemaal vooraan direct onder MI staan. In CASUS(90)
ging de geschikte kandidaat met de toegekende rol gaat
naar een gecreëerde landingsplaats direct voor de SF. De
semantische casusrol wordt in de huidige CASUS(92) echter
direct toegekend aan een succesvolle kandidaat. Die kandidaat
wordt gemarkeerd met het feature [+arg], dat dus aangeeft dat aan
deze constituent een semantische rol is toegekend. De constituent
is, met andere woorden, een (semantisch) argument van het
werkwoord.
Schematisch ziet de casusroltoekenning er zo uit:

De toepassing van Assign-Case wordt zo veel keer herhaald totdat er
geen casusrollen meer kunnen worden toegekend. Dit kan zijn wanneer SF leeg
is: er zijn geen casusrollen meer over. Het is echter ook mogelijk dat voor
een casusrol geen geschikte of bereikbare kandidaat gevonden kan worden
In dat geval vindt er verder geen toekenning meer plaats van de casusrollen.
Nu kan het zijn dat bepaalde complementen optioneel zijn of dat er
meer categorieën mogelijk zijn als complement. Optionaliteit
wordt in het Semantische Frame (SF) opgenomen. Daar is met het
feature [±OPT] gemarkeerd of de betreffende categorie
optioneel is of niet. In SF wordt het aantal mogelijke
categorieën bij een argument uitgesplitst in OR/AND-structuren.
Met regels worden de alternatieven onder de OR-knopen gesplitst en
verwerkt in afzonderlijke structuren. Een probleem kan ontstaan
als er meer categorieën mogelijk zijn voor een bepaalde
argumentpositie. Als een intern argument optioneel is, dan zouden
alle categoriale realisaties ervan ook optioneel moeten zijn. Maar
als alle mogelijke categorieën bij die argumentpositie als
optioneel worden gemarkeerd, dan zou in geval van het ontbreken
van het argument veel dezelfde analyses gegeven, doordat iedere
uitsplitsing een nieuwe structuur oplevert waarin telkens weer een
andere categorie die vanwege het optioneel zijn niet gerealiseerd
hoeft te worden, uit de verzameling mogelijke categorieën wordt
gekozen. In SF wordt dit probleem opgelost door slechts één
categorie van de mogelijke categorieën optioneel te laten zijn.
De rest van de categorieën zijn gewoon verplicht. De variant
waarin het interne argument ontbreekt, is dus mogelijk door die
ene optionele categorie niet te realiseren. Dit levert geen
ongewenste analyses op. Eigenlijk wordt het probleem van
ongewenste analyses door optionaliteit en opsplitsing in AMAZON/CASUS
indirect opgelost. Als een abstracter type wordt
genomen dan het type categorie, dan hoeft dit abstractere type
slechts één keer gemarkeerd te worden voor [±OPT].
Als dit [+OPT] is, dan wordt de argumentpositie wel of niet
bezet.
In het geval dat de argumentpositie wel bezet wordt, dan wordt het
argument gerealiseerd door een van de mogelijke categorieën. Als
dit [–OPT] is, dan moet de argumentpositie bezet worden door een
van mogelijke categorieën. De afzonderlijke realisaties hoeven
nu niet meer afzonderlijk met het feature [±OPT]
gemarkeerd te worden.
Er is nog een duidelijk punt waarin het AMAZON/CASUS-model
verschilt met de theorie. In AMAZON/CASUS is geen duidelijk
scheiding aangebracht tussen syntactische subcategorisatie
(subcat-frame) en semantische selectie (-grid).
Volgens de theorie zou dit wel nodig zijn. (Argumenten voor deze scheiding
zijn te vinden in paragraaf 2.3 over de
verwerking van subcategorisatie in G&B).
Deze twee soorten frames zijn in AMAZON/CASUS nu samengenomen in het
SF-frame. Dit SF-frame wordt gecontroleerd in één module,
namelijk de CASUS-module. Dit kan problemen opleveren. Zo is
er de vraag waar de ambiguïteit van de constructie als
hij geeft de oudste boeken in de grammatica behandeld moet
worden. Bij het werkwoord geven levert deze constructie
van headless NP met bare plural twee lezingen op, omdat het
interne argument (IA) met de Datief-rol optioneel is. Het hoofd
van de NP kan ontbreken, zoals in de NP de oudste (0), dat
"de oudste persoon" kan betekenen. Dit levert de variant op waar
de oudste de Datiefrol krijgt en boeken de
Objectrol. De variant met één NP de oudste boeken is
ook mogelijk, omdat het interne argument met de Datiefrol niet
verplicht is en dus mag ontbreken.
| | EA | | IA | IA
|
| 1. | hij | geeft | de oudste | boeken
|
| | +AGE | | +DAT | +OBJ
|
| | | | |
|
| | EA | | IA |
|
| 2. | hij | geeft | de oudste boeken |
|
| | +AGE | | +OBJ |
|
Bij een werkwoord als zien is echter maar één lezing
mogelijk: hij ziet [de oudste boeken]. Dit werkwoord heeft
een EA en een IA. Hier is alleen de analyse mogelijk met
de oudste boeken als IA-NP[+OBJ]. Er mogen geen kandidaten
overblijven die geen semantische rol toebedeeld hebben gekregen.
De opsplitsing in twee NP's [de oudste] en [boeken],
hetgeen twee aparte IA's zou opleveren, is daarom uitgesloten.
Er zou dan aan één argument geen -rol
toegekend kunnen worden. Ieder argument moet echter een -rol
krijgen van het werkwoord. Je zou zeggen dat dit volgt uit het
ProjectiePrincipe en -criterium. Maar de vraag is dan: waar
zouden deze principes moeten zetelen in de grammatica? Nemen we
subcategorisatie-eisen op in AMAZON of nemen we ze, zoals
nu, mee in de module CASUS waar casusroltoekenning
plaatsvindt? Het aantal en de aard van argumenten wordt nu immers
in het SF-lexicon vastgelegd bij ieder werkwoord. Nu zijn
subcategorisatie-frame en -grid in CASUS onder één
frame ondergebracht, namelijk: SF. De controle van de
subcategorisatie-eisen bevindt zich in het CASUS-gedeelte
van het AMAZON/CASUS-model. De subcategorisatie-controle en
de roltoekenning gebeurt dus in feite tegelijkertijd in AMAZON/CASUS.
Als typering van gesubcategoriseerde elementen
geldt categorieselectie (NP, PP, SE). Het onderscheid externe en
interne argumenten wordt gemaakt in de Grammatica van
casustoekenning: eerst het externe argument [+NOM], de eerste
argumentpositie in SF, daarna de interne argumenten [–NOM],
de niet-eerste argumentposities in SF.
Wat beter aan zou sluiten bij de theorie, is een scheiding van
subcategorisatie en thematische roltoekenning. De
subcategorisatie-eisen zouden dan verwerkt moeten worden in AMAZON:
er gelden dan syntactische restricties op de
constituenten van het MI-deel (nadat een eventueel getopicaliseerd
element is teruggeplaatst onder MI) die opgelegd worden door het
werkwoord (de lexicale kern). In CASUS zouden dan alleen de
thematische rollen aan de argumenten hoeven worden toegekend.
Hiervoor is een hertypering nodig van categorieselectie naar
argumentselectie: SF bevat dan alleen de typen EA en IA.
Thematische roltoekenning en optionaliteit van argumenten zou
volgens mij dan eenvoudiger kunnen in CASUS. Zo zou de
opsplitsing van OR-structuren en het smelten van AND-structuren
niet meer nodig hoeven zijn. En roltoekenning is nu een kwestie
van: kan een argument deze rol krijgen, los van de categorie van
het argument.
Deze benadering zal hoogstwaarschijnlijk weer nieuwe problemen opleveren.
Door een andere datastructuur veranderen eveneens de regels die hierop werken.
Daarbij kan er nu meer vaagheid of ambiguïteit in SF zijn. Misschien moet
categorieselectie als syntactische restrictie op de mogelijke kandidaten
toch erbij betrokken worden, om zo het aantal mogelijke kandidaten sterk
te reduceren. Misschien is er een patroon/regelmatigheid te ontdekken in de
volgorde van semantische rollen (vergelijk: Hierarchy of Obliqueness,
de relatieve ordening van semantische rollen).
De kracht zit in de (relatieve) eenvoud en de modulaire aanpak. In
wezen bouwen we dan een directe argumentstructuur op waar rollen
aan de argumenten worden toegekend. Misschien opent deze
benadering weer nieuwe wegen. Het zou mooi zijn als zaken
vereenvoudigd kunnen worden. Bovendien wordt de AMAZON-grammatica iets
strikter: niet alle structuren worden zomaar toegelaten.
Er moet immers ook aan de subcategorisatie-eisen worden voldaan.
Het AMAZON/CASUS-model zou in dit opzicht gewijzigd moeten
worden. De scheiding tussen syntaxis en semantiek wordt dan
duidelijk tot uitdrukking gebracht: subcategorisatie hoort bij
syntactische module AMAZON en rolverdeling van semantische
rollen valt onder de module CASUS. Bovendien kan het
probleem van kale meervoudsvorm (bare plural) na een
hoofdloze (headless) NP hiermee opgelost worden.
Hierboven heb ik proberen duidelijk te maken hoe subcategorisatie
in het AMAZON/CASUS-model verwerkt wordt. Verder heb ik
aannemelijk proberen te maken dat er enkele fundamentele
wijzigingen in het model nodig zijn om het model beter aan te
laten sluiten bij de theorie.
Voor opmerkingen of vragen over deze pagina kunt u contact opnemen
met Simon van Dreumel
Laatst gewijzigd op 25 augustus 2025


