Voor de data in het corpus zijn enkele kant-en-klare frequentielijsten afgeleid, met daarin informatie over de frequentie van voorkomen van woordvormen, tags en lemmata en combinaties hiervan.
Ook is er een frequentielijst beschikbaar van woordvormen en hun fonetische transcripties.
Sommige woordvormen in de lijsten werden van een code voorzien, die iets zegt over de status van de desbetreffende woordvorm.
De volgende codes kunnen voorkomen:
'foreign' voor vreemdtalige woorden; bv. wonderful/foreign
'incomplete' voor afgebroken woorden; bv. knelpu/incomplete
'mispr' voor al dan niet opzettelijke versprekingen; bv. contactueren/mispr
'regionalpr' voor zwaar dialectisch uitgesproken woorden
'uncertain' voor moeilijk verstaanbare woorden
| totalph & totrank | |
| een alfabetische respectievelijk 'rank ordered' woordfrequentielijst met daarin de frequentie van voorkomen van woordvormen, over alle data in het CGN met hierin de volgende kolommen : | |
| # de rangorde van voorkomen van de woordvorm (alfabetisch / van hoog- naar laagfrequent); | |
| # de totale frequentie van de woordvorm in het gehele corpus; | |
| # de woordvorm. |
| areaalph & arearank | |
| een alfabetische respectievelijk 'rank ordered' woordfrequentielijst waarbij onderscheid gemaakt wordt tussen de Vlaamse data en de Nederlandse data, met hierin de volgende kolommen : | |
| # de rangorde van voorkomen van de woordvorm (alfabetisch / van hoog- naar laagfrequent); | |
| # de totale frequentie van de woordvorm in de Nederlandse data; | |
| # de totale frequentie van de woordvorm in de Vlaamse data; | |
| # de totale frequentie van de woordvorm in het gehele corpus; | |
| # de woordvorm. |
| typealph & typerank | |
| een alfabetische respectievelijk 'rank ordered' woordfrequentielijst waarbij een uitsplitsing wordt gemaakt naar de 15 componenten die in het corpus worden onderscheiden, met hierin de volgende kolommen : | |
| # de rangorde van voorkomen van de woordvorm; | |
| # de totale frequentie van de woordvorm in component a; | |
| # de totale frequentie van de woordvorm in component [...]; | |
| # de totale frequentie van de woordvorm in component o; | |
| # de totale frequentie van de woordvorm in het gehele corpus; | |
| # de woordvorm. |
| nltypealph & vltypealph | |
| een alfabetische woordfrequentielijst met betrekking tot de Nederlandse respectievelijk Vlaamse data waarbij een uitsplitsing wordt gemaakt naar de 15 componenten die in het corpus worden onderscheiden, met hierin de volgende kolommen : | |
| # de rangorde van voorkomen van de woordvorm in de Nederlandse data; | |
| # de totale frequentie van de woordvorm in het Nederlandse deel van component a; | |
| # de totale frequentie van de woordvorm in het Nederlandse deel van component [...]; | |
| # de totale frequentie van de woordvorm in het Nederlandse deel van component o; | |
| # de totale frequentie van de woordvorm in de Nederlandse data; | |
| # de woordvorm. |
| tagalph | |
| een alfabetische frequentielijst van POS-tags, gestructureerd als volgt : | |
| [woordsoortfrequentie] [woordsoort] [tagfrequentie per woordsoort] |
| lemalph | |
| een frequentielijst van lemmata met bijbehorende woordvormen en POS-tags, gestructureerd als volgt : | |
| [NL-freq. lemma] [VL-freq lemma] [tot. freq. lemma] [lemma] | |
| [NL-freq. woordv.-tag] [VL-freq. woordv.-tag] [tot. freq. woordv.-tag] [tag] [woordvorm] |
| fonalph | |
| een frequentielijst van tokens (woordvormen) met bijbehorende fonetische transcripties, gestructureerd als volgt : | |
| [NL-freq. woordvorm] [VL-freq woordvorm] [tot. freq. woordvorm] [woordvorm] | |
| [NL-freq. uitspr.] [VL-freq. uitspr.] [tot. freq. uitspr.] [uitspr.] |
| RANK | TOT | TOKEN |
|---|---|---|
| 1: | 941685 | . |
| 2: | 309774 | ja |
| 3: | 262631 | dat |
| 4: | 248660 | de |
| 5: | 226189 | en |
| 6: | 205181 | uh |
| 7: | 184619 | ik |
| 8: | 172044 | een |
| 9: | 141417 | is |
| 10: | 138235 | die |
Zoeken op frequenties in Corex
Om frequentie-informatie te verkrijgen in verband met de orthografische, prosodische en fonetische transcriptie en in verband met de
part-of-speechtags en lemma’s van woorden, kunt u gebruikmaken van de zoektool “Statistics” in Corex. U vindt deze in het hoofdmenu van
het Corex-openingsvenster onder “Search”.
Alvorens een query in het Statisticsscherm in te voeren en op te slaan, moet u één of meerdere (sub)corpora toevoegen aan de lijst van te doorzoeken fragmenten. Als u bijvoorbeeld wilt zoeken in de subcorpora “news” en “spontaneous conversations” moet u het volgende doen : in de “Metadata Descriptions Tree” dubbelklikt u op “Components”. In de lijst die tevoorschijn komt, kunt u (dubbel) klikken op “spontaneous conversations”. Wanneer u vervolgens nog een keer klikt op “spontaneous conversations” en op de button “Add” onderaan het venster, dan wordt die component toegevoegd aan de lijst van te doorzoeken fragmenten : alle zoekacties die u vervolgens uitvoert zullen alleen in de spontane conversaties uitgevoerd worden. De component “news” voegt u op dezelfde wijze toe aan de lijst. (Let erop dat u de lijst van te doorzoeken fragmenten (de “basket”) ook weer leegmaakt wanneer u een zoekactie op een ander deel van de data wilt doen. De “basket” leegmaken, doet u door op “Clear” te klikken.)
Nu er subcorpora geselecteerd werden, kunt u in het Statisticsscherm één of meer query's definiëren. Bv. zoals in de onderstaande screenshot : zoek op vreemde woorden en versprekingen (in de subcorpora "nieuwsuitzendingen" en "spontane spraak".
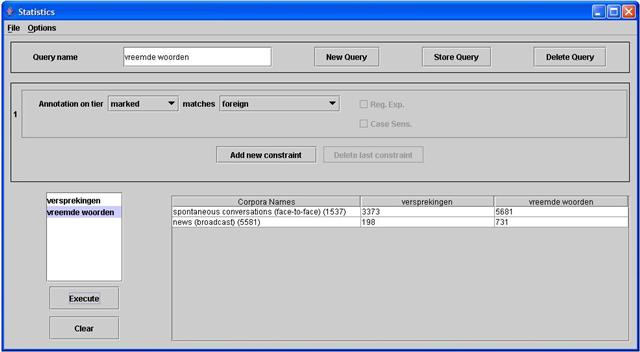
Houd er wel steeds rekening bij dat de subcorpora een verschillend aantal woorden bevatten en dat het hier om absolute cijfers gaat.
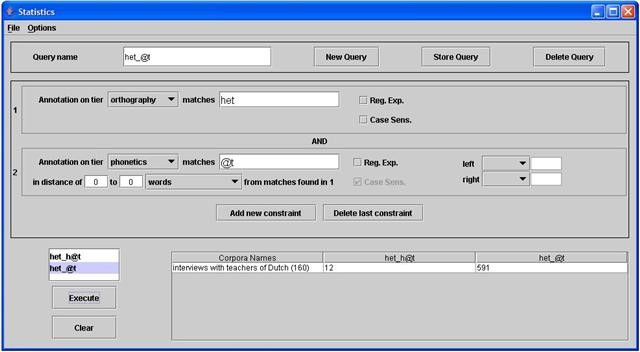
Het is ook mogelijk om een meerledige zoekactie te doen : er kunnen meerdere zoekcriteria ingevoerd worden door op “add new constraint” te klikken : die zoekcriteria kunnen betrekking hebben op dezelfde annotatielaag, maar er kan ook gezocht worden binnen verschillende annotatielagen. Dat is bijvoorbeeld het geval wanneer we frequentie-informatie zoeken over het woord “het” uitgesproken als /h@t/ en /@t/ in de component interviews met leerkrachten Nederlands.