Metadata van het CGN slaat op een grote hoeveelheid informatie over de sprekers en de fragmenten in het corpus.
Uitgebreide info
Naast audiobestanden, transcripties en annotaties omvat het corpus tevens metadata die nadere informatie geeft
over de fragmenten en de sprekers die erin voorkomen. Onder sprekergegevens verstaan we onder andere het geslacht,
het geboortejaar, de geboorteplaats, de geboorteregio, de opleiding etc. De fragmentgegevens bestaan uit onder andere
de beschikbare annotaties, het aantal woorden in een fragment, duur van het fragment, opnamedatum etc.
Zoeken op metadata in Corex
De metadata kan gebruikt worden om subcorpora te definiëren.
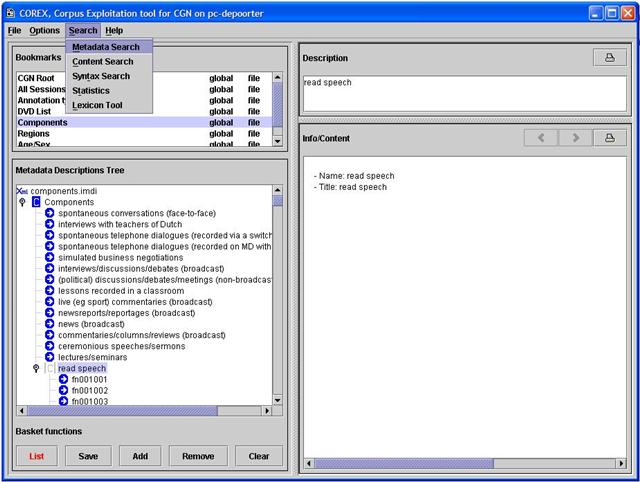
Om op de metadata te zoeken, kunnen we gebruikmaken van de “Metadata Search” in Corex. U vindt deze in het hoofdmenu
van het Corex-openingsvenster onder “Search”. In het hoofdscherm van Corex heeft u al de mogelijkheid om een (grove)
selectie te maken uit de data door bijvoorbeeld alleen alle voorgelezen tekst te selecteren: in de “Metadata Descriptions
Tree” dubbelklikt u op “Components”. In de lijst die tevoorschijn komt kunt u dubbelklikken op “read speech”.
Wanneer u de component “read speech” selecteert en op “Add” klikt, zullen alle zoekacties die u vervolgens uitvoert
alleen in de voorgelezen teksten plaatsvinden. Hierna kunt u het subcorpus verder specificeren door naar de “Metadata
Search” te gaan. Let erop dat u na uw zoekactie(s) de lijst van te doorzoeken fragmenten (de “basket”) ook weer leegmaakt
door op “Clear” te klikken (bijvoorbeeld wanneer u een andere zoekactie wilt doen), anders blijft alleen het subcorpus
geselecteerd.
In het scherm van de “Metadata Search” zijn er verschillende menu’s, aan de hand waarvan u de zoekcriteria kunt vastleggen. Wanneer u de “Metadata Search” opent, ziet u “Session-Name” staan : u kunt dan bijvoorbeeld alleen de Vlaamse data selecteren binnen het component “read speech”. Alle Vlaamse fragmenten beginnen met de aanduiding “fv” in de fragmentnaam, dus in het tekstvakje na “Session-Name” vult u “fv*” in. (De asterisk is een “wildcard” en wil zeggen “elk mogelijk karakter van nul tot n keer”). Met andere woorden: het criterium “Session-Name-fv*” zorgt ervoor dat er alleen maar gezocht wordt op Vlaamse fragmenten. Let op dat u altijd op “enter” drukt na het invoeren van een query, pas dan verschijnt het criterium in het tekstvak onder “Query specification and results”.
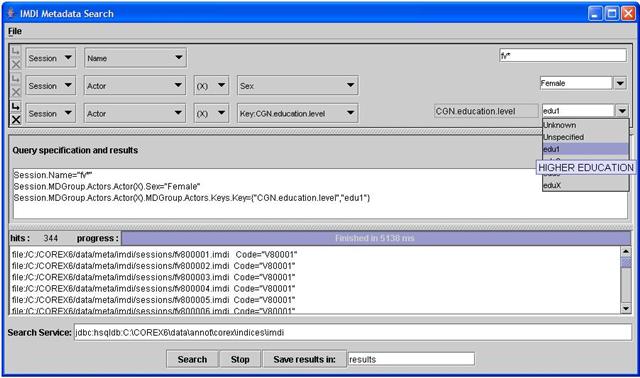
Om nog een zoekcriterium toe te voegen, klikt u op het pijltje links naast “Session”. Nu kunt u bijvoorbeeld het criterium “zoeken op alle vrouwen” definiëren. Hiervoor moet u de menuoptie “Actor” kiezen in het menu onder “Name”. (Wanneer u met de demo werkt, moet u de menuoptie "Participant" kiezen). Na deze actie uitgevoerd te hebben, verschijnen er opnieuw een aantal menu’s. De “X” is een variable, deze moet u veranderen als u bijvoorbeeld op mannen en vrouwen zoekt binnen eenzelfde fragment. Onder het menu “Role” vindt u de optie “Sex” waarna u “Female” selecteert in het laatste menu.
Om vervolgens nog verder te specificeren wat bijvoorbeeld opleidingsniveau betreft, voegen we nog een constraint toe.
We kiezen weer “Actor” (of "Participant" voor de demo), laten de X staan (het gaat immers om dezelfde personen) en kiezen in het volgende menu het
“education level”. De code “edu1” staat voor hoogopgeleid (de codes vindt u hier).
Na het definiëren van de zoekcriteria kan de zoekactie gestart worden door op “Search” te klikken.
Als we vervolgens de zoekresultaten opslaan onder een zelfgekozen naam hebben we een subcorpus gedefinieerd dat bestaat
uit uitingen uit de component “voorgelezen tekst” van hoogopgeleide Vlaamse vrouwen.
We vinden ons nieuw aangemaakte subcorpus terug door te klikken op “Search Results” in het “Bookmarks”-venster van het
Corex-hoofdscherm. Wanneer we het subcorpus selecteren, kunnen we het toevoegen aan de lijst van te doorzoeken fragmenten
(de “basket”) en kunnen er zoekacties op uitgevoerd worden.